在Gemini3出现之后,使用AI编程的质量有了大幅提升。使用AI辅助开发产品,成本也大幅下降。以前1个sprint(2 weeks)完成的feature,现在可能1-2个下午就搞定了。但更重要的不仅仅是使用AI模型以及对应的工具,而是知道自己需要什么样的产品,以及是不是能够通过AI实现出来。纵观从GPT-3.5-turbo到Gemini-3-pro,工具依旧需要人来驾驭,尽管这个过程中所谓专家的技术护城河越来越低,不过同时也说明了作为安全工程师需要能够更好的学习使用对应工具。借此机会,把近几年使用AI编程的实践总结一下。
0x01. 整体设计:从Prompt开始
设计越详细,输出越可靠
从最初的prompt工程开始看起,其实也是随着模型一直在变化。随着模型自己能够reasoner模式并开始thinking。prompt似乎变得有些无关紧要了。但实际则是不然,个人感觉只是模型能够更好的根据你的意图去规划推理prompt中的逻辑。真要在做产品的过程中,则需要你完整的制定prompt。(除非你不知道自己的产品想要做成什么样的,而是完全依赖模型的输出,否则一定是要设计prompt的。但这里在AI编程实践中的prompt和之前博客里提到过的prompt engineering又稍有不同,这里不会关注在prompt中的“诡计”, 而是关注如何通过prompt完整描述编程过程中想要的设计(以下内容以在Cursor中进行AI编程为例)。
一般会分为几块:
- 主要的技术栈: 鉴于我python编程较为熟悉,一般会指定使用python,并且告诉Agent其使用哪些主要的lib,比如B/S架构的产品我一般会要求使用fastapi,数据库使用SQLAlchemy,密钥相关使用Cryptography, 模型相关如果涉及到Gemini会使用Google的专有库google-generativeai,其他的会使用Openai的库,以及本地会用llama_index,还有服务端用AI网关的库用于支撑多模型。这样避免AI自动帮你引用了一些可有可无的、过期的缺乏维护的、存在漏洞的library
- 目录结构和文件结构: 好的目录结构,后续在增加feature和发现bug测试的过程中极为有效,且能够更好的使用多Agent模式进行编程(意味着你拥有了多人协作的研发能力)。对于Python项目而言,一般我会需要其具备schemas目录,models目录,services目录,api目录,db目录,如果设计任务调度则会要求具备worker目录(使用worker一般会在技术栈里要求使用celery)
- 数据库: 因为技术栈里要求使用了ORM的库,其实可以忽略后端的DB类型,即便迁移,也会方便很多。在本地开发的时候,可以使用sqlite快速原型,之后同步迁移到postegre。但需要注意的是,应该在早起对数据库的schema进行定义,分别具备哪些table,哪些字段
- 业务核心逻辑:
- 服务能力: 比如以PKI服务为例,需要要求具备CA能力,Issue证书的能力(主要是把这些逻辑写进去,比如step 1: load/generaete private key, step 2 validate CSR, step3 sign the ceritficatem, step 4 return PEM data), 以Encryption As A Service为例,会要求Receive KeyObject/ID,然后怎么decrypt,最后return nonce + ciphertext to user等。 这些其实一般会放在前面说的service目录里。
- 接口能力: 其实不论需不需要对外提供API,都应该设计API接口的业务逻辑,因为至少需要前后端分离过程中能够通过API进行通讯。这个时候,需要设计关注哪些对外暴露的接口,其API的schema需要怎么设计,例如request需要什么样的字段,response需要什么样的字段。
- 安全相关的编码: 编程语言本身的(避免常见的注入,secret相关的需要主动要求配置分离等);业务逻辑本身的(例如要求decrypt仅发生在内存里);基础功能相关的(用户管理,RBAC,SSO集成等);但实际情况是,出产品原型的过程中大概率不会考虑这个板块,而是在基础功能完善之后才会增加。回到前面目录结构和文件结构的重要性就体现出来了,这个时候后续增加的模块逻辑能够很好的无缝衔接,实现出来。工程化代码一定要使具备安全能力,安全业务的产品更需要产品安全,但实际实现最初没有关注到所安全,这一点是需要反思的。
- 界面(UI)基础:其实网上有几种说法,一种是一键clone对应的页面,或者image to UI这种,但是这些基本上都是demo玩乐,真正需要自己实现产品的时候,一定需要有界面的设计。不过这里可以只设计基础的部分指定一些风格(mui, tailwindcss),具备哪些component,widget即可,真到css style(font size, color)什么的反而不必要关注,可以在后续对话中进行调整。(一定会进行调整,尤其是前端部分)
- 实现步骤: 告诉Agent从上到下如何进行实现(上面几块+这一段需要组成一个完整的prompt),例如先实现基础的DB Schema部分,然后实现核心的业务逻辑,接着提供API接口功能,最后实现看板功能。通过分步实现告诉Agent如何去工作
⚠️注意,其实也可以通过告诉模型你的需求,让其帮你设计。只需要告诉模型通过system thinking的模式(即便模型可以帮助你thinking,但还是建议你告诉模型使用system thinking你的需求,并且拆分validate,verify他的输出设计),帮你去细节化整体的设计,也是可以达到类似效果的。但是需要注意的是,这个过程则需要你关注在需求细化。所有前面的技术描述都转换为,你需要XXXX,在YYY输入的情况下,应该获得XXX的输出。最后就是review整个prompt。然后丢给Cursor编写代码。 点击此处访问Prompt示例,该prompt是Gemini 3根据设计自动生成的最初版本。
0x02. 细节调整:测试及修复Bug
必须要测试/验证 Agent写的feature, 并发现Bug进行修复。(你必须实践过才知道下文提到的bug是什么)
Cursor Agent + Gemini 3虽然能够很好的生成代码,但是对于复杂的产品和较底层的逻辑,实现起来一定是bug的。100%。这也就是为什么我在前面的博客中提倡使用TDD的方式去编写对应的代码。
这里会列出一些遇到的问题类别,以及调优和使用技巧。(以下所指均基于Cursor Agent和Gemini 3进行)
- 包管理和路径管理类问题
- 经常出现在Autorun的过程中,pip包安装失败;此类解法首先避免使用system env,为项目的project创建独立的venv,其次如果有可能应该尽量的使用uv(Use UV in cursor rules)替代pip去管理包,并编写rules告知
- 命令执行失败的问题,此类大部分是由于路径不对导致,解法可以在sanbox的autorun之外,编辑命令行。也可以主动使用绝对路径。
- 模型幻觉类问题
- 模型认为其使用了对应的内容。例如指定了模型上下文对话过程去调用工具,并根据返回的工具进行下一步预判。尽管工具调用成功,调用工具依旧会输出Simulated Report,此类问题解法可以通过加强system instructions,使其必须等待真实输出,拒绝自行模拟。同时增加工具的等待时延,要求异步任务必须在获得结果之后向模型发送。
- 模型认为其实现了对应逻辑,但实际没有: 例如CRL没有写入到证书文件,但agent一直在笃定自己实现了这个feature。 此类问题的解法是告诉Agent对应的标准(例如这里是X509),通过对规范的引用及更细节的处理过程实现具体逻辑。参考上一节业务核心服务能力部分prompt,当时需要告诉业务的具体运行逻辑。这里通过引入每个业务过程中涉及到的更底层逻辑来矫正模型的代码输出。
- 业务逻辑类bug
- 状态(Waiting Status)类的展示问题:比如有N个RAG Knowledge base,增加batch processing & index 按钮之后,documents list开始one by one的进行更新,但是总的waiting status不发生改变,在最终procssing完之后依旧是waiting状态,需要手动刷新浏览器窗口。这类问题的解法一般是: 为session id增加status字段用来刷新, 第二种方式分离API接口,例如workflow的状态展示可以使用单独的websocket接口进行更新,而非使用混在模型正常输出流里使用标签类字符
- 复杂架构类的问题,对于B/S架构出现较少。但针对B/C/S类架构比较麻烦,例如提供了B/S结构的管理功能用作服务端,同时使用Client注册到Server端提供端侧能力,并将该Client本地监听端口,作为Brower Extension的Server。由于涉及到不同类别的语言栈,模块划分等。此类问题的解法通常是: 分离作为两个项目实现,避免在一个复杂的Project里实现。B/S分离一个,Client分离一个,Brower Extension分离一个。 当然也可以设计更为详细的Prompt,指定每一部分的交互逻辑。
- DB表的刷新,部分情况下新增的业务逻辑会导致表结构的变化,但Agent不会自动解决表结构的问题(他只触发了修复业务逻辑的能力,而没有触发业务逻辑映射到DB的问题),主程序main.py自动的reload就会导致SQLAlchemy报错。针对此类问题的解法:单独启动一个agent,专门用于处理backend类的问题。你可以将类似的其他的backend类的error统统的放到该agent下面去运行即可。除此之外,再用一个Agent把所有的db类操作(init,update)代码移动到一起即可。
- 产品界面类bug:这个可太多了
- Cursor编辑器本身的bug
- 在一次输出被reject之后,并进行了revert之后。同时调整prompt删去了其中某一个需求(假设原始需求有3个,删掉一个还有2个),但在执行时,Curor有时会仍旧记忆了旧的需求(依旧是3个需求)。这个时候一般是Agent自身的ToDo列表没有更新掉,此类问题的解法:在拒绝输出的代码后,如果设计调整需求时,可以在revert的prompt那里采用直接情绪化输出。骂人即可。
- 跨服务的修改文件,这个bug比较严重。起因是在A项目里新起了个agent,prompt让其按照 http://localhost:5174 的界面调整当前界面。结果导致其夸项目修改了5174下的代码。且执行过程中,点击allow按钮允许运行代码的过程中,没有意识到已经跨项目了。还在疑惑,平常都是autorun,根本不需要去手动点击。直到发现5174界面报错,才发现原来之前的允许执行的代码已经跨项目被更改掉了。 此类问题暂时没有找到解法,只遇到了一次。只能快速的revert并修改prompt,仅让其check the ui, 不在让其follow the style.
还有一个关于界面类的bug,我并没有详细列出来。因为这种类型的bug根据业务场景的不同和交互逻辑的不同一定会重复出现很多次。例如设计的一个chat类应用,同模型进行chat的过程中,在返回结果前一般会进行waiting,但如果点击其他对话之后如果某个对话在waiting,会导致所有其他UI同步显示waiting。这种bug简直不要太多,还有点击对应agent进行对话,默认就会带入第一个agent,而不是指定界面上的agent。这类问题的解法没有统一的,首先肯定是要确定自己的业务逻辑是什么。然后进行调整即可。
关于调整,则需要先能够知道什么是widget,component,page, panel,module,box,window, sidebar等,同时能够精准的描述位置, within, under,in the left/right of , center, bottom, top,fixed, relative等,然后告诉你是想update xx style, follow xx style, move it, popup, alert it, double confirm, bring it into等等
其实就是能够精准描述对界面组件的调整。 某个element在某个位置,我想要他怎么怎么样即可。但这里其实也会出现模型幻觉类问题,我在一个产品的实现过程中。header 部分的标签宽度一直都是不符合的,且造成了其他按钮的遮盖。这个时候对话了4-6轮,模型依旧是认为设计了x个column里占了x个。哪怕情绪输出了2轮,check了所有的这个页面的代码,还是不行。最终的结局办法是进入到代码里,看对应的代码,然后手动修改的。最后固化为style rules记录下来。
针对功能调整的优化,一般来说英语做prompt很有必要的,即便你可以说模型本身会帮你进行语言转换,我也尝试了用中文在Cursor里和Gemini3对话调整UI,效果并不太好。另外就是尽量使用MAX模式而非Auto模式,需要注意的是有些模型(以Sonnet4.5为例)默认上下文空间是200K,使用MAX模式之后,虽然支持1M的空间,但超出200K的部分会快速的产生高额计费。(意味着一次对话输入可能花费1-2美金),所以务必要详细的指定你的prompt的需求。直白直观的告诉他需要什么。
0x03. 风格迁移:学习Rules
如果我前面写的prompt和bug修复能够被理解且进行了实践,其实已经可以做出对应的产品了,此时如果你还想进一步研发具备相同风格的产品,作为一条风格鲜明的产品线,你就需要设定Cursor Rules了。
当然你也可以先dump出来,或者让Agent把你当前满意的一个产品的风格记录下来。(这也意味着可以最先原型一个最小需求的产品,用来验证其后端编程风格,前端编程风格以及其他风格的可用性,之后记录下来用于夸大产品)
让Agent输出你的前端风格
@Codebase I want to reuse the frontend style and component patterns from this project in a new project that will have a completely different backend. |
让Agent输出你的后端风格
@Codebase Act as a Senior Software Architect. I want to start a new project and I want to strictly follow the coding style, architectural patterns, and best practices established in this current backend codebase. |
之后将各自输出分别命名为frontend-style.mdc和backend-style.mdc,然后在新的项目里面新建一个文件夹.cursor/rules, 如果你像我之前还遇到过包管理的问题和header头无法修复的问题,可以再创建类似python-package-management.mdc和header-fix-style.mdc, 但是需要注意的是,单个rules文件也不建议内容太长。
一般我建议放置以下类别的rules:
- 后端编程风格
- 前端编程风格
- 包管理的风格(比如倾向于使用uv来管理Pyhton的包)
- 安全编程的风格
这是我的一个后端编程风格的rules
|
好的编程风格其实意味着好的架构设计,新的需求特性能够快速的衔接进来,模型能够以较少的token去获得对应的解题思路。同时也能够使用多个Agent并行工作。但做产品最开始的永远不是编码,而是需求,从需求到产品之间充满了另一种设计上的思考和平衡。
0x04 闲话
无论是talk is cheap, show me the code还是code is cheap , show me the prompt, 时代在变化,工具在变化,但最终还是需要人去使用工具。从严重依赖AI进行编程的朋友那里经常听到吐槽:“以前是写代码的时间多,调Bug的时间少。现在是AI写代码的时间快,调Bug要两三天”。在概率分布的前提下,永远不可能有100%的完美实现。但得益于AI Coding能够对原型的快速实现,让人能够更关注到需求本身的交付而不需要关注背后的实现。不过这个并不适用于大型项目。自从GPT3.5 Turbo出现之后,我就尝试用用AI编程做过的一些尝试。但在Gemin-3出现以后,在编码尝试之后发现,用于大型项目不再是不可能。
限于之前Ai Studio的API Key只是Tier 1,因此充值了Cursor的20$会员,接着发现并不够用,于是改充了60$的会员,然而依旧不够用,开了50$的On-Demand,两天不到又刷掉了40$多,想了一下最终换成了200$的会员。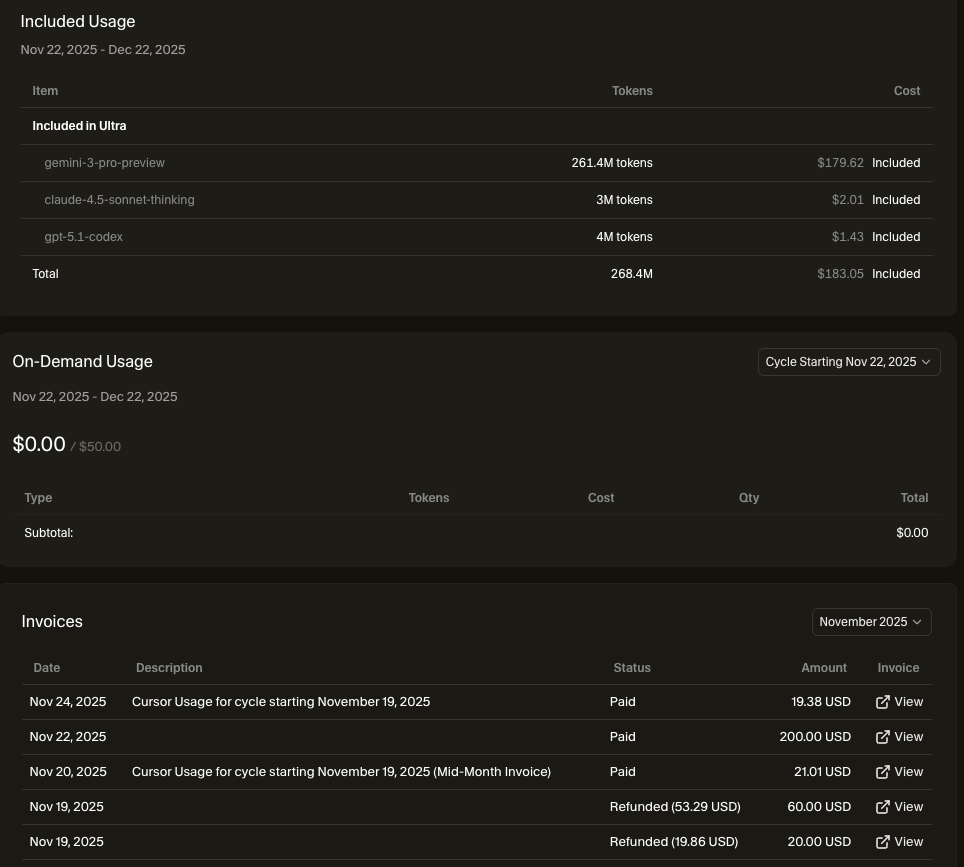
但是算了一下,针对设计和实现的产品来看,虽然相对价格较高。但对于研发而言,成本可谓极低。(截图内仅用了一周,实际编程可能5天的样子)
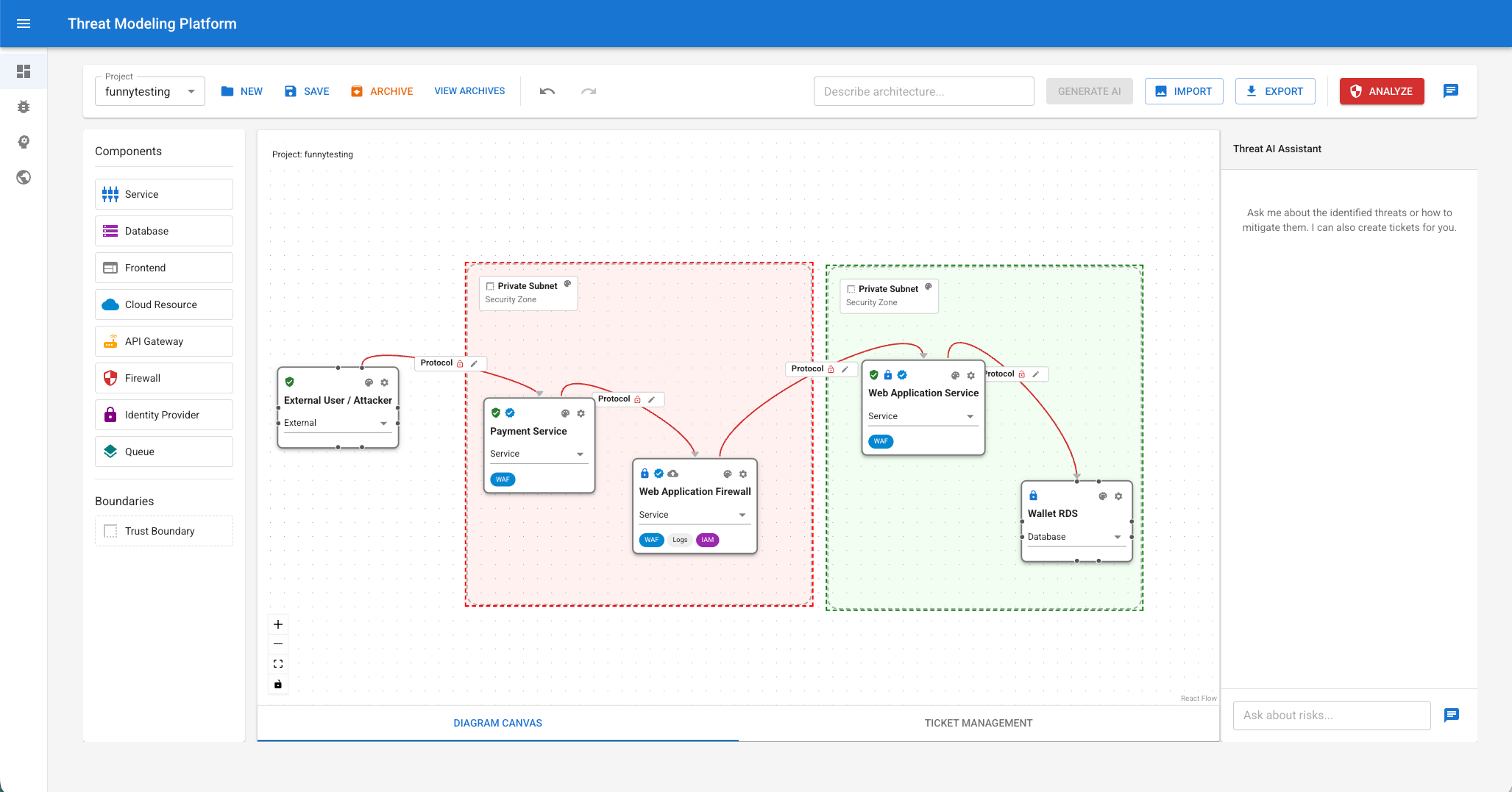
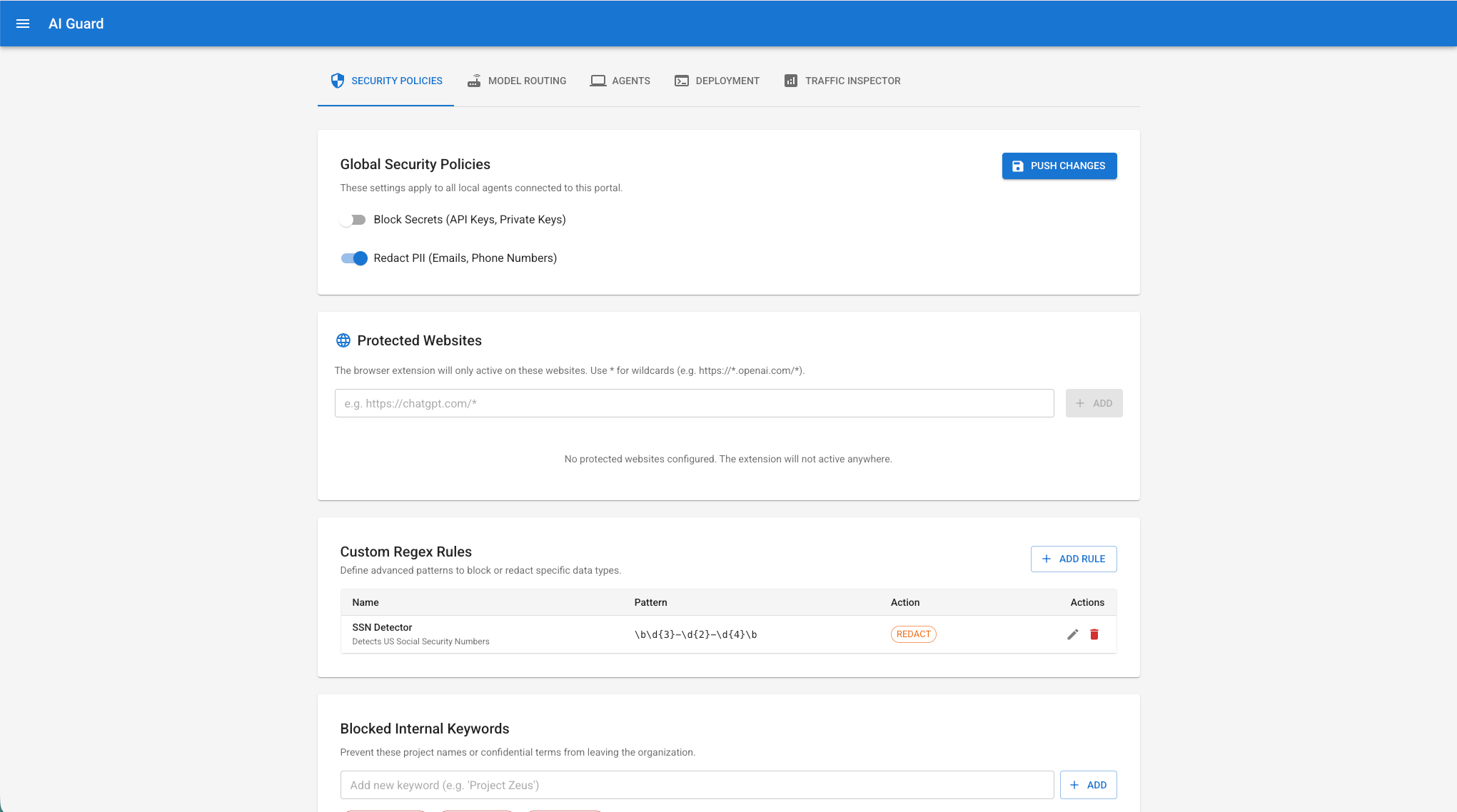
以下为部分产品的UI示例截图(最近做的,终于感觉像是产品不是工具和服务了):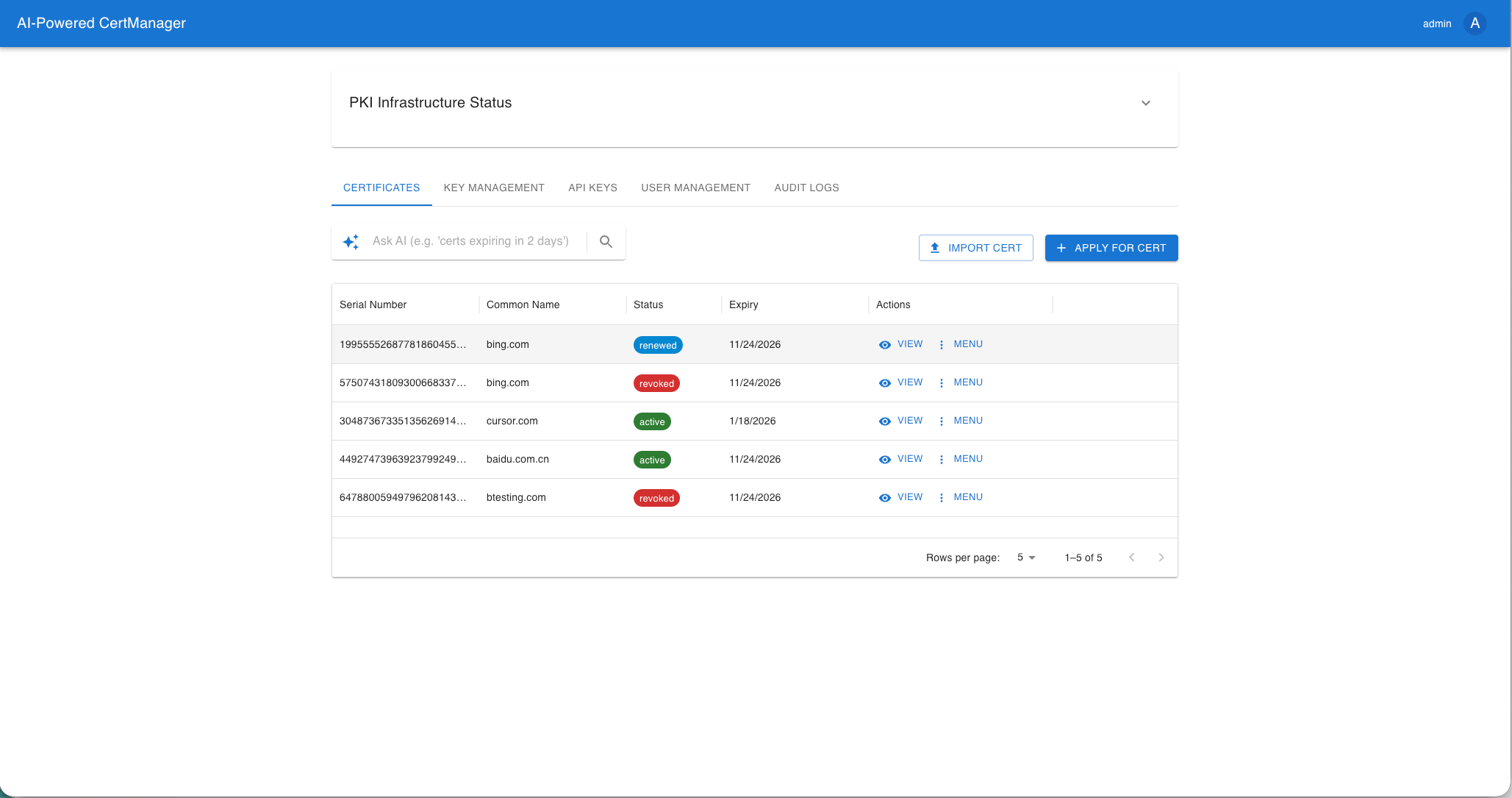
最初是从4月份开始计划写AI驱动产品设计的总结,到7月份又调整了一版(把Python编程单独拎出来整理了一篇)。本来今天准备把《AI编程和产品设计实践》写完,但写到产品设计已经觉得冗长,遂重开一篇。《产品设计心得》下篇见!

以下是按原目录写博客时列举的用AI做过其他的一些工具,暂列于此(时间顺序排列,但不如最近一两月感觉更像企业类型的产品,见前述图):
- Web版本的Code Review(Python+Flask,作用是输入一段代码,能够识别漏洞及Code Review。后端接的模型是GPT-4o)
- 工作时用到的各种小工具箱 (HTML-based)
- Mac平台上的阅读Bot(基于Python,用来在阅读PDF时遇到不懂的地方直接截图,后台会进行summary & research, 后端接的是GPT-4o)
- Apple Watch的一个六爻卜卦应用(Swift语言, Cursor编辑器)
- 随机一卦(一个基于web的类似万剑飞行特效的,这种css完全不会,全靠AI,但是由于事后没有学习这个AI写的CSS代码,所以显的也很傻瓜)
- CISSP考试工具(纯前端应用,JS+React,使用了Claude2.7,Gemini2.5分别做过不同的版本)
- AI Browser (Nodejs+Electron, 最初设想是浏览器驾驶窗,AI实时的接收浏览器的上下文,并给出分析)
- Vault平台(Pyhton+Flask, Java+Javalin. 一个支持EAAS,多CA集成,证书管理和机构证书管理签发的平台,PS:AI可以把300人天变成30人天)
- 回测平台(Python+streamlit, 实现了一个常见策略回测的可视化小工具)
除此之外一些Web的样式的调整(例如博客,书单网站等),类似SRC的Security Center宣传页面等,以及还有一些原型的设计:
- Solution Craft(希望通过一个平台实现企业在管理整个产品研发流程时能够involve到不同的部门进行资源管理,并能默认嵌入SDLC以及DevSecOps,支持多种框架的mapping)
- 神灯阿拉丁(一个关注留守儿童心理健康的平台)